
栈论 : 递归与栈式访问,如何用栈实现所有递归操作(幼儿园题目篇,题目3)
上一篇 :
栈论 : 递归与栈式访问,如何用栈实现所有递归操作(幼儿园题目篇,题目2)
题目3
这一题,乍一看和之前题目间明显的区别是什么呢?没错,聪明的你可能已经想到了,子函数要和父函数通信了,子函数需要告诉父函数a或b在不在自己这里,自己有没有找到a或b。
如果我们把二叉树的每个节点都抽象成一个节点带着左边一大片的左子树,和右边一大片的右子树

那么我们只用分以下几种情况讨论
1.如果节点的左子树找到了a或b中的一个值,而右子树中找到另一个值,那么当前节点就是我们要找的最近祖先节点了。
2.如果其中一颗子树找到了a或b中的一个值,但是另一颗树没有找到另一个值,说明另一个值可能在另一颗子树里 ( 例: 左子树找到了a 但是右子树没找到b 说明b可能在左子树里)
3.左右子树都没找到任一一个值,说明当前节点需要被排除
4.比较特殊的情况
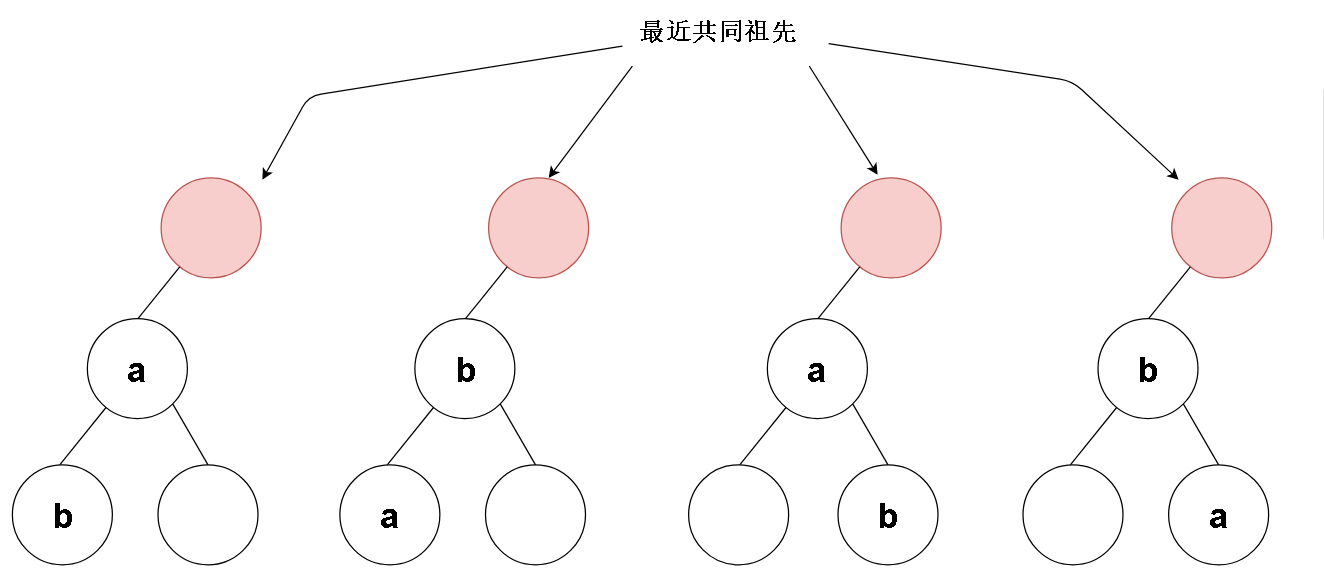
把思维反转一下,从低向上地思考,好像处了特殊情况4外其他情况都是下图这种 。有待查找值的节点最终会向中间交叉汇聚,得到我们的目标节点
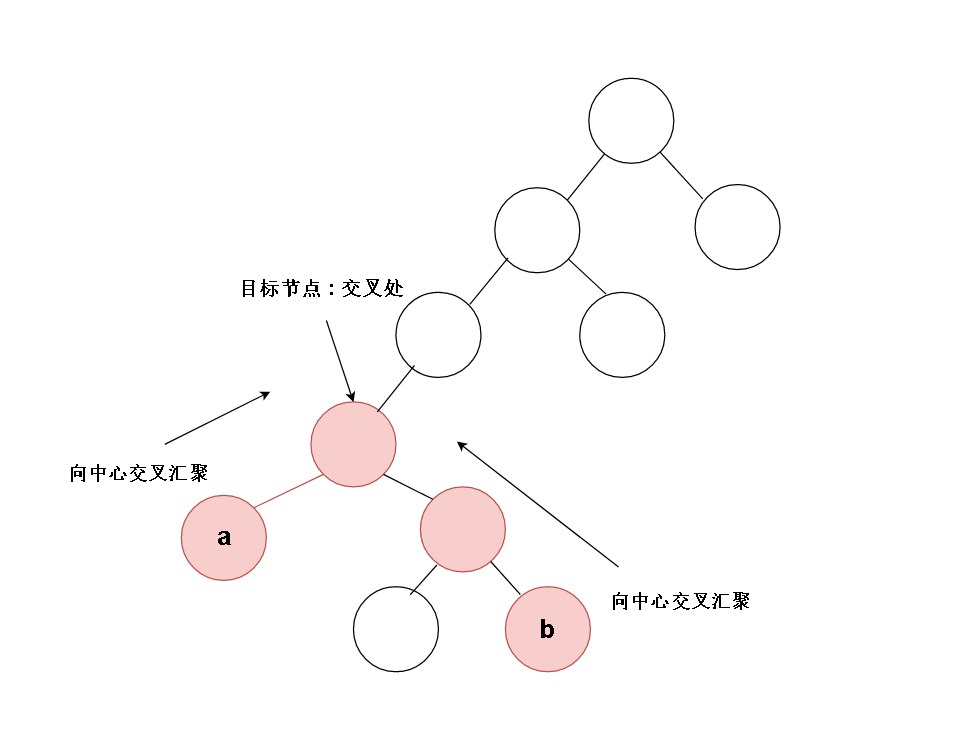
如果我们在递归中把对子函数的调用放在最前面,把对自己的处理放在最后边(正如后序遍历)。那么对二叉树的访问,总是会呈现自底向上的访问效果,而访问子节点的子函数和父函数之间是能通过返回值进行信息传递的,那么左右节点找到的信息会自底向上地交汇到我们地目标节点那,目标节点知道了一切,于是他确定自己是最近地共同祖先。
但是要时刻注意,无论是递归还是我们的栈式实现,最终只能有一套方法处理栈帧,我们的父子栈帧交流也只有一套。怎么设计这一套交流机制呢?
1.一个节点需要为他的父节点汇报消息
2.一个节点需要问他的左右孩子节点,有用的信息
节点间交流的信息应该是一个值,而且是和a,b同类型的值(char)就够了,用来告诉父节点是否找到了。
对于点1
1.节点自己的值就是一个待查找的其中一个值
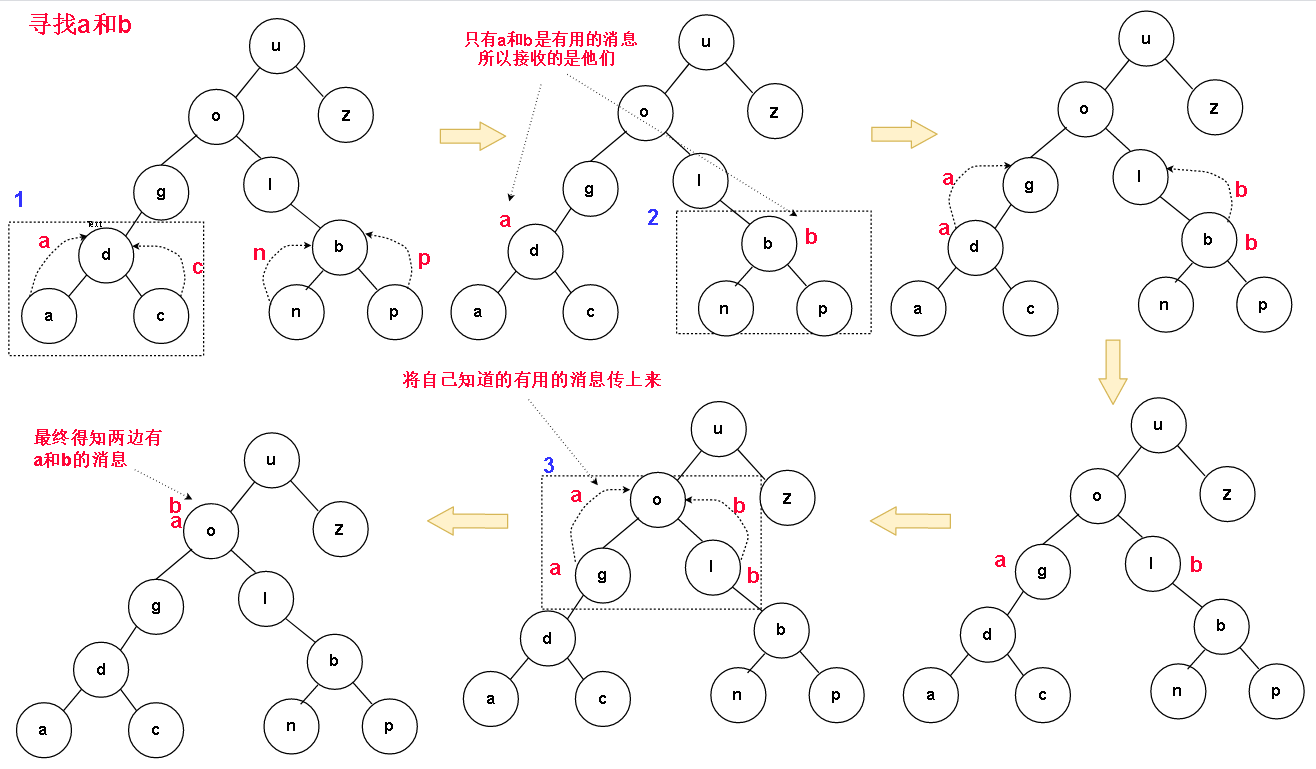
查看左右两个孩子传来的值,如果其中有另一个值,那么当前节点的父节点就是我们的目标节点(对应特殊情况的配图)。如果左右孩子中不存在另一个值,那么就将自己的值传上去(上图框2中的值为p的节点)。
2.如果自己节点的值根本就不是查找的目标值:
左右孩子传来的值正好是那对我们查找的值(上图中值为o的节点),说明当前节点是我们的目标节点。而如果左右字节的传来的值中只有一个是目标值的话,就将这个值传上去给当前节点的父节点(上图框1中值为d的节点)。如果左右传来的值里没一个是要找的值,那么也不知道传什么,把自己的节点值传上去吧,反正也不是要找的值,就表示没找到。
有思路吗?如果没有的话可以先试试写下递归来实现。
char,BiTree findNearestAncestor(BiTree tree, char a, char b){
if(tree == NULL){
return -1;
}
char lv = findNearestAncestor(tree->lchild);
char rv = findNearestAncestor(tree->rchild);
if(tree -> data == a || tar -> data == b){
if(lv == a || lv == b || rv == a || rv == b){
return parent;//直接返回父节点,这里写的是伪代码,所以假设可以直接找到当前节点的父节点,实际上在递归的栈帧通信中要把父节点作为形参才能这么做。
}
return tar -> data;
}
if(lv ^ a ^ rv ^ b){ // 如果(lv,rv)是(a,b)或者(b,a) 那么 a^b^a^b = b^b^a^a = 0 , 也就是lv 和 rv 一对值和 a ,b一对值对应的时候 结果是0,所以走的是else分支
//以下是a b 不对应 lv rv 的结果
if(!((lv ^ a) & (lv ^ b))){ // lv和其中a b 其中一个相同 : ( lv ⊙ a) + (lv ⊙ b) = !!(( lv ⊙ a) + (lv ⊙ b)) = !((lv ⊕ a) * (lv ⊕ b))
return lv;
}
if(!((rv ^ a) & (rv ^ b))){ // rv和其中a b 其中一个相同 : ( rv ⊙ a) + (rv ⊙ b) = !!(( rv ⊙ a) + (rv ⊙ b)) = !((rv ⊕ a) * (rv ⊕ b))
return rv;
}
}else{
return tree; //如果左右子传来lv rv 和 a b 对应上,那么目标节点找到了 就是当前节点
}
}
你可能会问,嗯???怎么会有两个返回值???是的,就是两个,记得之前我们研究方法栈帧间父子函数通信的方式么?是的,子函数在寄存器eax上遗留值,让父函数去捡,这就是一个返回过程,那么我们为什么不能安排两个寄存器呢?把两个值分别仍在两个寄存器那里,让他们成为两个返回值给父函数捡。
下面我们来安排栈帧该有的信息:
从函数调用的参数(BiTree tree, char a, char b)大概可以总结为
1.当前节点
2.待查找的a的值
3.待查找的b的值
另外还需要一个值作为方向舵,判断当前节点是否将左子函数栈帧,右子函数栈帧入栈以及当前栈帧是否弹出。
而且我们发现每个栈帧要查找的值是不变的,也就是a和b的值是不变的,所以a 和 b 可以提取出来,不作为栈帧信息,而是作为全局信息存在(类似eax寄存器)。
最重要的一点是,父函数的栈帧需要保存子函数在eax中留给自己的值,因为其他的子函数会把eax的值覆盖掉!
平时我们看到的类似如下的代码,好像是两个东西返回值值加相加,但实际上是一个返回值要先暂存起来,等另一个返回值覆盖了eax之后,再加在一起
int a = add(1, 2) + add(3, 4);
return a;

而类似我们的 char lv = findNearestAncestor(tree->lchild);
这种形式,如同下面,也是要一个变量的内存空间存储的。

我们直接把返回值存储在栈帧中,改正一下,我们的栈该有的信息:
1.当前节点
2.方向变量
3.左/右子函数返回的值
相比之前 栈帧多了成员lret,rret 分别表示左函数返回值和右函数返回值:
typedef struct FunctionFrame {
BiTNode * node;
char lret, rret; //一开始都设置为 -1,表示还没有赋值过
int tag;
};
实现代码 : 请深吸一口气,平复一下心情再看。
BiTree findNearestAncestor(BiTree tree, char a, char b) {
Stack stack;
init(stack);
FunctionFrame frame;
int initial;
int original;
initial = 0b0011; //初始值 表示两边都还要调用
original = -1;
init(stack);
frame = { tree, (char)original, (char)original, initial };
push(stack, &frame);
char ret = original; //相当于eax
while (!stackEmpty(stack)) {
FunctionFrame* frame = getTop(stack); //不能随便弹出,因为父子函数栈帧之间需要进行通信
if (frame->tag & 0b0001) { //如果最低位是1
if (frame->node->lchild != NULL) { //左孩子节点不为空
FunctionFrame* lc = (FunctionFrame*)malloc(sizeof(FunctionFrame)); //创建左子节点的函数栈帧
lc->node = frame->node->lchild;
lc->tag = initial;
lc->lret = lc->rret = original; //一开始都设置为 -1,表示还没有赋值过
push(stack, lc); // 左子函数栈帧入栈
frame->tag = frame->tag & 0b0010; //将最低位(调用左子函数的标志)抹除掉
continue; //左子函数栈帧入栈 右子函数就不要入了,因为要等待左子函数调用完右边才能调用
}
}
//因为有调用左边的continue阻挡,所以到了这里表示已经从左子函数返回了
if (frame->lret == original) {
frame->lret = ret; // 这时候就该把左子函数返回的值保存起来
}
//右边情况和上边的左边类似
if (frame->tag & 0b0010) {
if (frame->node->rchild != NULL) {
FunctionFrame* rc = (FunctionFrame*)malloc(sizeof(FunctionFrame));
rc->node = frame->node->rchild;
rc->tag = initial;
rc->lret = rc->rret = original;
push(stack, rc);
frame->tag = frame->tag & 0b0001;
continue;
}
}
if (frame->rret == original) { //其实也可以不用加 rret这个变量的,因为到了这一步直接用右子函数返回的值就可以了,不用保存
frame->rret = ret;
}
char mine = frame->node->data;
char lv = frame->lret;
char rv = frame->rret;
if (lv ^ a ^ rv ^ b) { //如果(lv,rv)和(a,b)或者(b,a)不相同
if (!((lv ^ a) & (lv ^ b))) { //lv和a或b之中一个相同 当前节点返回lv
ret = lv;
}
if (!((rv ^ a) & (rv ^ b))) { //rv和a或b之中一个相同 当前节点返回rv
ret = rv;
}
if (mine == a || mine == b) { //如果当前节点的值是要查找值中的一个
if (lv == a || lv == b || rv == a || rv == b) { //如果左边或者右边传来的值是要找的另一个
pop(stack); //当前节点直接出栈 直接去找他的父节点
if (stackEmpty(stack)) { //如果栈是空的 表示根节点的值是我们要查找的值,根节点无祖先,返回空
return NULL;
}
else {
return pop(stack)->node; //直接返回当前节点的双亲节点
}
}
ret = mine; // 如果左右传来的值中没有要找的,那么就返回自己的值
}
}
else {
return frame->node; // 左右传来的值正好都是要查找的值 当前节点就是目标节点
}
pop(stack); // 调用完成后出栈
}
return NULL; // 栈空了都没找到,表示两个节点不全在树种
}
从题目可以看到。
1.我们的栈实现方式,可以以局部变量模拟寄存器的形式,在逻辑上返回多个返回值
相当于我们有这样的函数:
char,int,bool get(){ //相当于有了return + 返回编号 这样的形式
return1 'c'; //作为第1种返回类型返回
return2 3; //作为第2种返回类型返回
return3 false; //作为第3种返回类型返回
}
2.另外,一般栈的大小是小于堆的,我们把栈帧的开辟转移到了堆上,可能访问速度有所下降,但对于处理数据大的函数,可能可以防止栈溢出,但不能防止堆溢出。
3.可以让子函数强行和父函数通信,获得父函数的某些信息,如上面直接就把父函数栈帧出栈并且返回父函数栈帧里的节点了。
4.减少栈帧中的变量,如果这些变量在递归函数的调用中作为形参时不会变,或者变得很少。
当然缺点也不少:
1.代码复杂,烧脑
2.如果栈是建立在堆上的话,访问速度会下降
3.我们是用软件来模拟硬件层次的操作,所以效率多多少少会下降
更多幼儿园题目还在上线中......
护眼绿:
没人看的结语:
首先很感谢你看到这里,辛苦了。
文章中某些地方可能不正确或不准确,代码也可能不够高效可读,希望读者能够帮忙指正,共同学习进步。

